Kaggle DeepLearning 강의, 문제풀기 (ing..)
15 Sep 2019 | deep learning programming dl본 포스팅은 https://www.kaggle.com/learn/deep-learning 강의를 학습하고 정리하였습니다.
1. Intro to DL for Computer Vision
텐서플로우와 케라스에 대해 설명한다. 텐서플로우는 유명한 딥러닝 툴이고, 케라스는 유명한 딥러닝 모델을 구체화하는 API 또는 인터페이스이다.
케라스는 텐서플로우에서 돌아갈 수 잇는 딥러닝 모델을 만들어준다.
이 강의에서 다룰 것은 딥러닝에서 어떻게 이미지를 인식하는지 배워본다. 이미지는 간단하게 매트릭스(행렬)로 표현한다. 흑백 이미지의 경우에는 행렬 하나에 이미지의 밝기값을 담고 있을 것이고,
컬러 이미지의 경우에는 다차원 배열로 구성되며 R,G,B 채널로 이루어져 있다.
이 강의에서 말하는 ‘tensor’의 경우에는 보통 다차원 행렬을 의미하지만 나중에 더 자세히 다룬다.
컨볼루션이란 작은 ‘tensor’이고 필터라고도 부르는데 작은 컨볼루션 필터를 이미지에 거치고 나면 특정한 패턴을 추출할 수 있기 때문이다.
Exercise 1
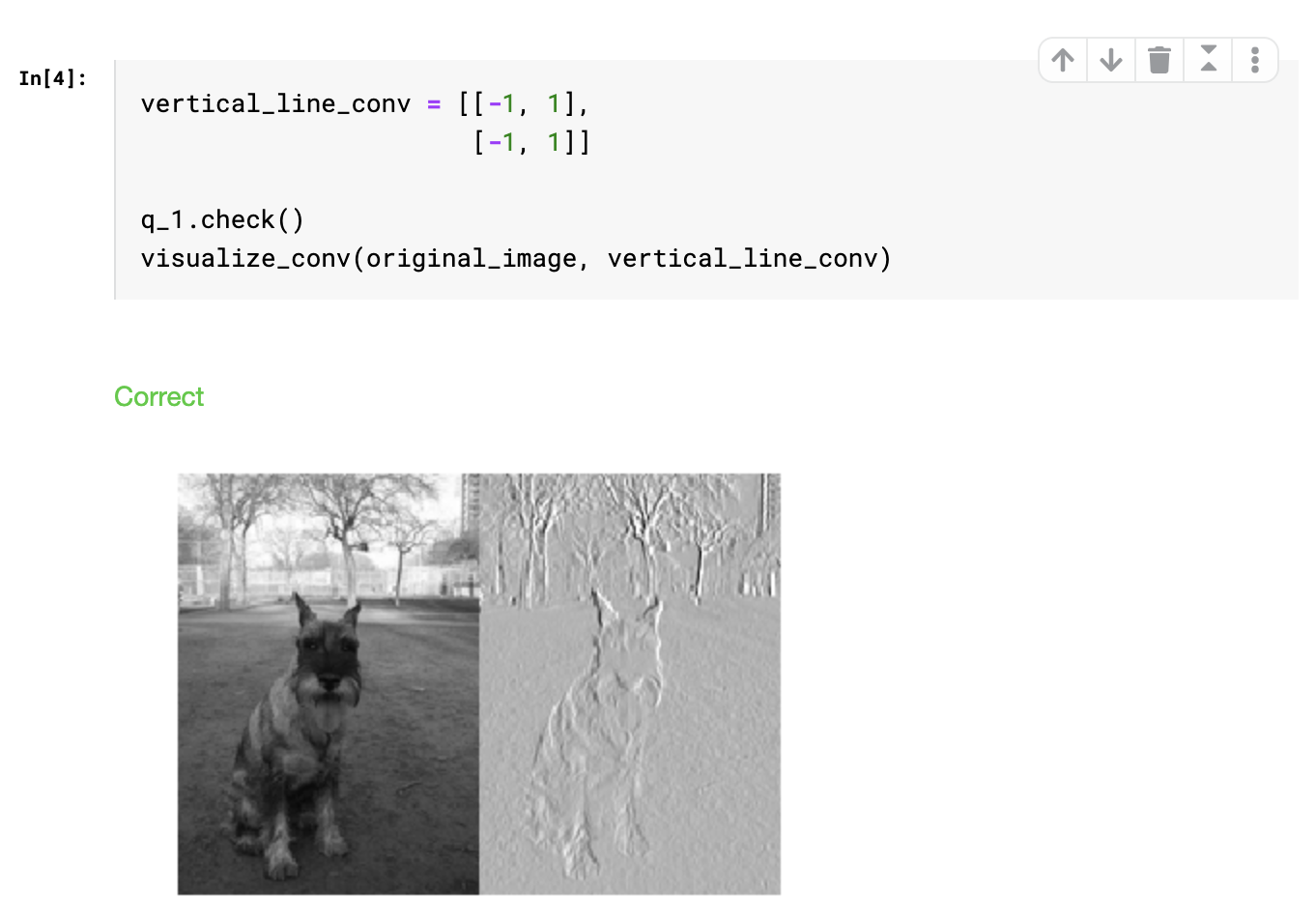
이것은 horizontal line을 찾는 컨볼루션 필터이다. vertical line을 찾으려면 행렬을 어떻게 변경해야 하는가?
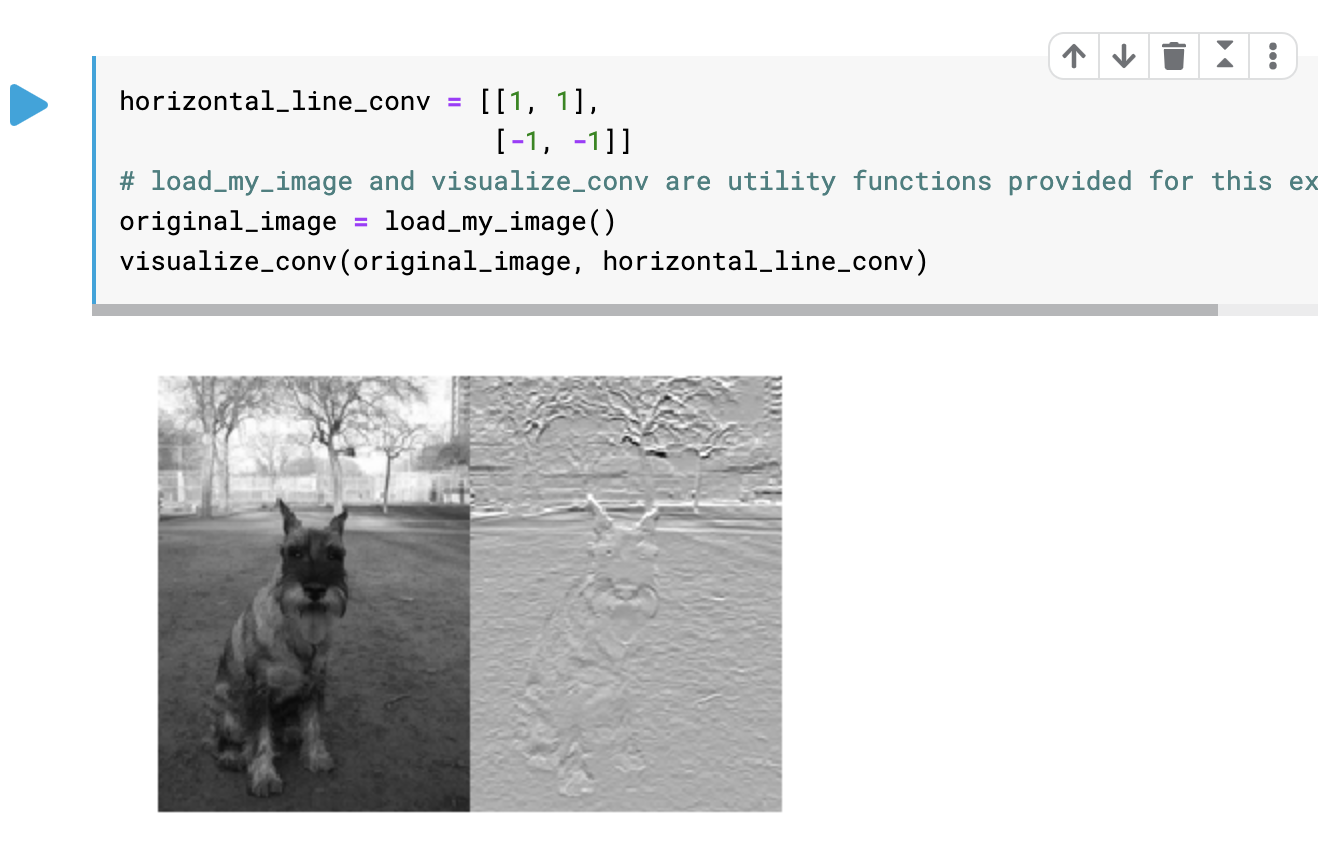
이렇게 -1의 위치를 세로로 바꿔주면 된다.
Exercise 2
지금까지 봤던 컨볼루션의 크기는 2x2 였다. 하지만 더 큰 컨볼루션 사이즈도 가질 수 있다.
3x3이나 4x4도 가능한 것이다. 또한 정사각형 일 필요도 없다. 그렇다면 큰 사이즈의 컨볼루션이 더 좋을까? 꼭 그렇지만은 않다.
다음 강의에서 딥러닝 모델이 다수의 컨볼루션을 합쳐서 복잡한 패턴을 찾아내는 것을 배울것이다.
2. Building Models From Convolutions
한 이미지를 가지고 여러개의 필터를 적용하는것이 가능하다. 이때 여러개의 필터를 한번에 적용하는 과정을 하나의 레이어라고 한다.
이 레이어들이 다음 레이어의 컨볼루션으로 변경되어 전달되게 되고, 결국 더 복잡한 패턴들을 찾을 수 있다.
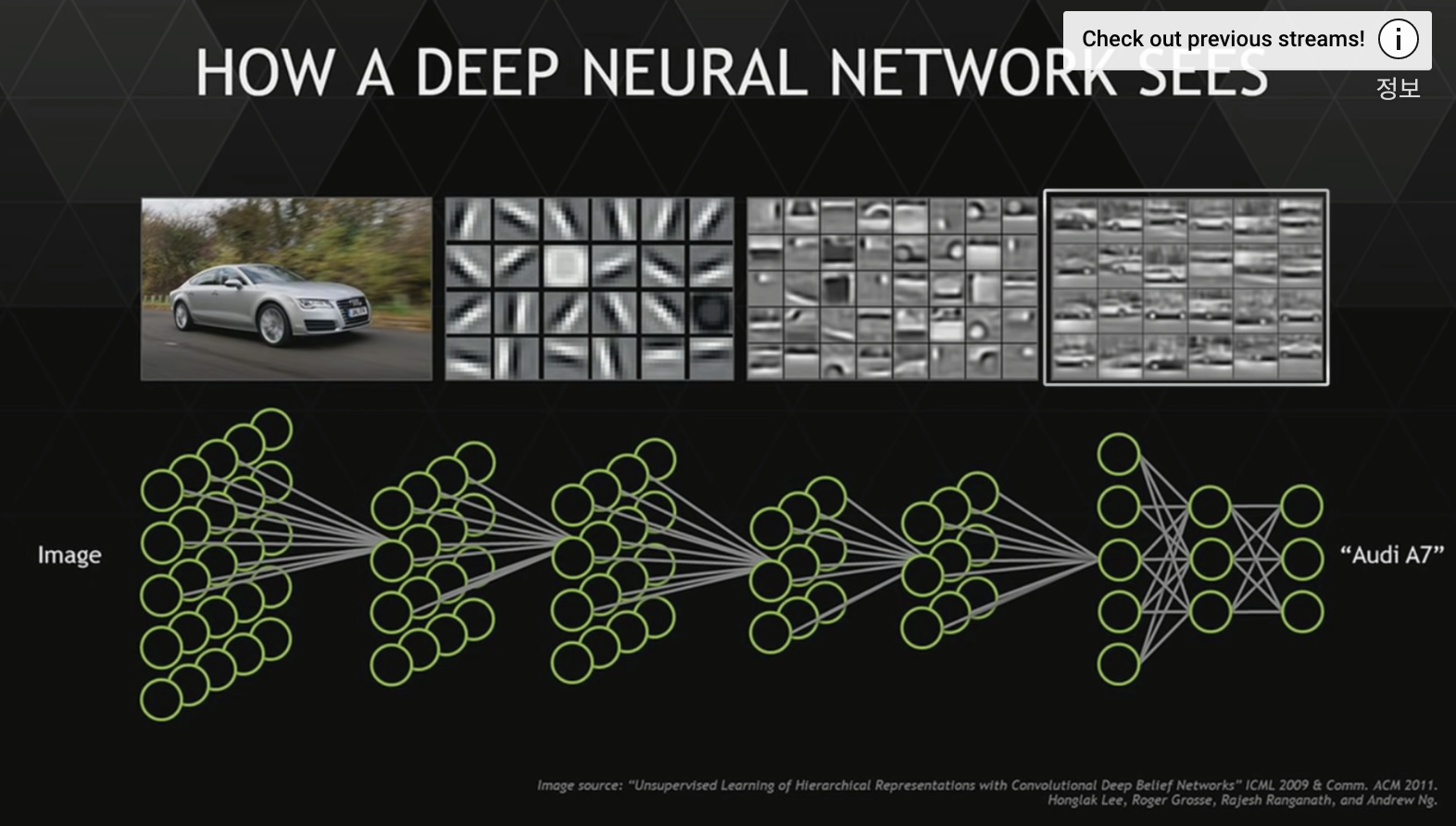
Exercise
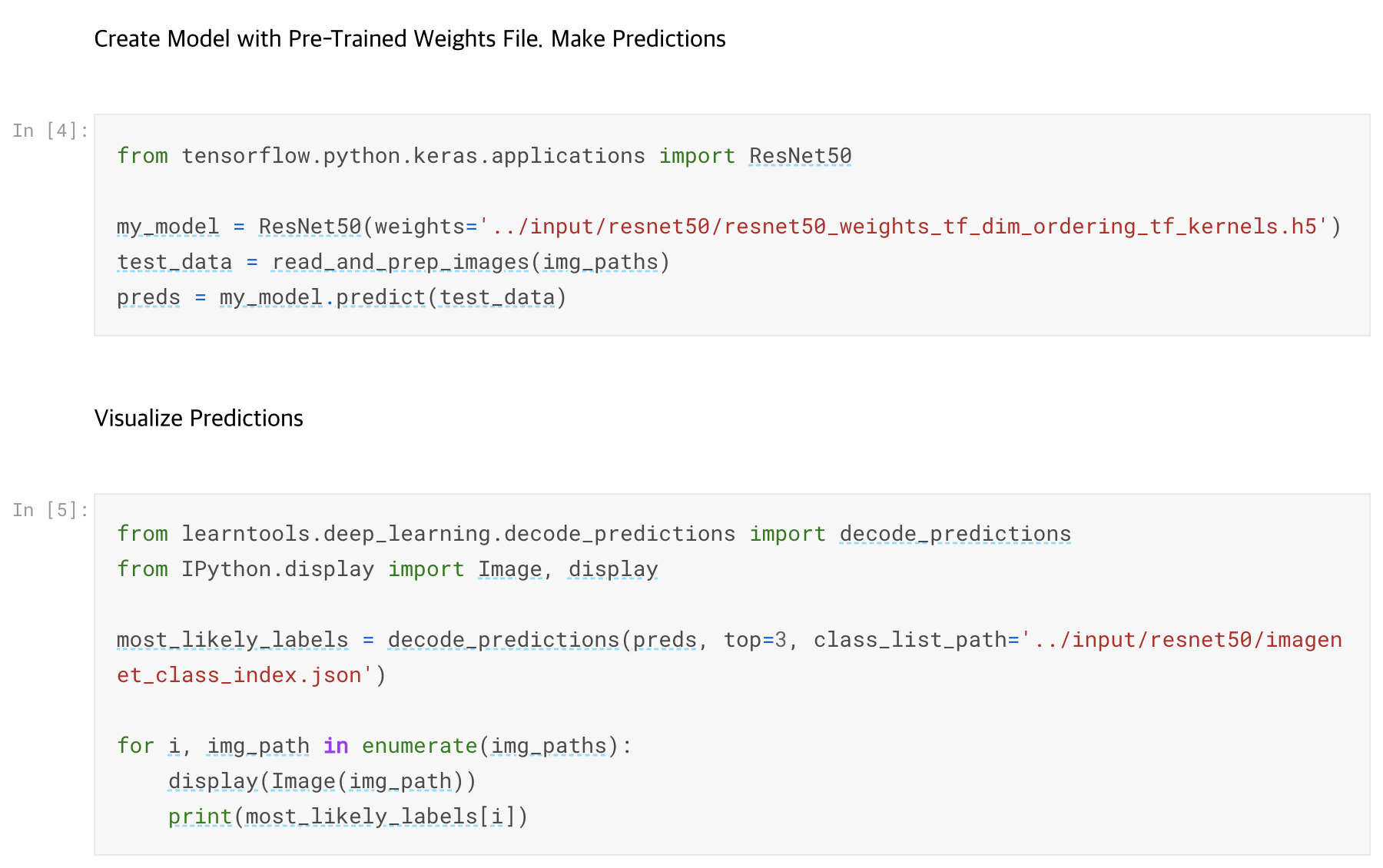
캐글에 미리 학습되어 있는 모델을 가지고 이미지를 분류하는 것을 실습해본다. 먼저 이미지를 읽고 전처리를 하는 과정을 거친다.
여기서는 ResNet50을 사용한다.
- tensorflow keras의 load_image를 사용하여 이미지를 불러온다
- numpy의 array를 사용하여 이미지를 array로 변경, 필요한 전처리 한다
- keras 라이브러리를 통해 미리 학습된 가중치 파일을 통하여 ResNet50 모델을 생성한다
- 모델을 사용하여 예측한다
- decode_predictions를 통하여 결과를 시각화해 본다 (라벨 출력)
3. TensorFlow Programming
Exercise 1
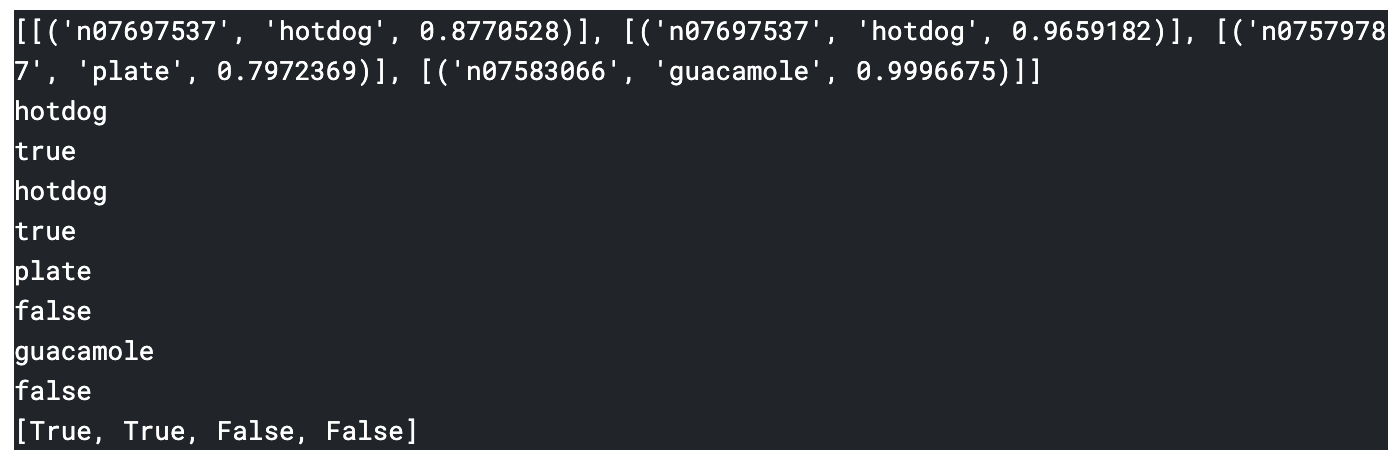
TV쇼 ‘실리콘 밸리’는 ‘Sea Food’라는 음식을 구분하는 앱을 가지고 있다. 이것을 구현해 보자.
- 이미지 패스를 만든다. 핫도그와 핫도그가 아닌 그림들이 구분되어 있다.
- 데이터와 미리 학습된 모델을 불러오고, 예측한다
- 예측을 시각화한다
이에대한 코드가 이미 구현되어 있고, 예측된 결과를 가지고 새로운 함수를 구현해본다.
예측된 라벨을 가지고 핫도그인지 아닌지를 Boolean값으로 변환하는 함수를 만들어본다.

Exercise 2
모델의 정확도를 평가하는 함수를 작성하라.
4. Transfer Learning
지금까지는 미리 학습된 모델을 사용하였다. 이런 경우에는 미리 학습되었던 카테고리별로 분류하는 것이 매우 쉽다.
하지만 만약 이런 모델에 새로운 카테고리를 추가하려면 어떻게 해야할까? 만약 이미지를 시골인지, 도시인지 구분하려면 처음부터 학습해야 할까?
‘Transfer Learning’ 은 비교적 적은 데이터를 가지고도 좋은 결과를 낼 수 있도록 해준다.
ResNet Model의 경우에는 많은 레이어를 가지고 있는데, 마지막 레이어를 잘라내본다. 그리고 새로 추가할 카테고리 노드들을 마지막 레이어에 추가한다.
마지막 레이어와 카테고리 노드들을 모두 연결하고, 소프트맥스를 적용한다. 소프트맥스는 노드를 확률로 반환해준다.
##Exercise 1
5. Data Augmentation
이미지를 flip하면 도시 이미지가 새로운 도시 이미지가 된다. 따라서 2개의 이미지로 학습할 수 있다.
ImageDataGenerator에서 horizontal_flop을 True로 하면 이미지를 여러개로 사용하여 학습시킬 수 있다. 하지만 글자를 학습시키는 경우에는
이런 경우가 통하지 않기 때문에, 상황에 따라서 Augmentation을 할지 선택하야 한다. flip 외에도 회전, 이동을 사용할 수 있다.
6. A Deeper Understanding of Deep Learning
가중치와 Gradient Descent Algorithm, Loss Function, Back Propagation에 대해서 알아본다. 또한 배치와 에폭 사이즈에 대해서도 알아본다.
인풋 레이어 세개와 예측 레이어 2개를 Dense Layer로 연결했을 때, 노드 사이에 가중치가 있다. 이를 forward-propagation을 통해서
최종 값을 계산할 수 있다. 이 때 하나의 값으로 추리기 위해서 Softmax 함수를 사용한다. Softmax는 결과값을 확률값으로 변환해 준다.
Loss Function은 모델의 예측이 얼마나 좋은지를 평가한다. 실제 값과 예측 값을 인자로 사용하여 Loss값을 구하는데, Loss값이 클수록 예측과 멀어진다는 뜻이다. Gradient Descent Algorithm은 Loss값이 최저가 되는 곳을 찾는 방법이다.
Batch Size는 학습할 때 한번에 사용하는 이미지의 양이고, Epoch는 전체 데이터를 학습하는 횟수이다.
7. Deep Learning From Scratch
transfer learning은 모델이 원래 존재하는 경우 사용한다. 하지만 모델을 처음부터 만드는 방법도 필요하다. 예를 들어 MNIST 데이터가 있다고 하자.
또한 MNIST for Fashion이라는 저해상도 옷 이미지를 가지고 분류하는 데이터가 있다고 하자.
이를 CSV포맷으로 읽을 수 있다. 먼저 이 파일에서 전처리를 하여 픽셀데이터를 0~1 사이로 바꾸는 등의 작업을 한다.
그 다음, 모델을 만드는데 레이어를 하나하나씩 추가한다. Conv2D를 사용하여 하나하나씩 추가하고 마지막에 모델에 배치사이즈, 에폭을 설정하여 fit 한다.